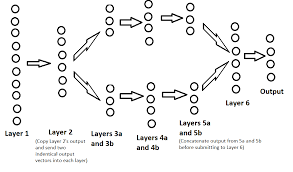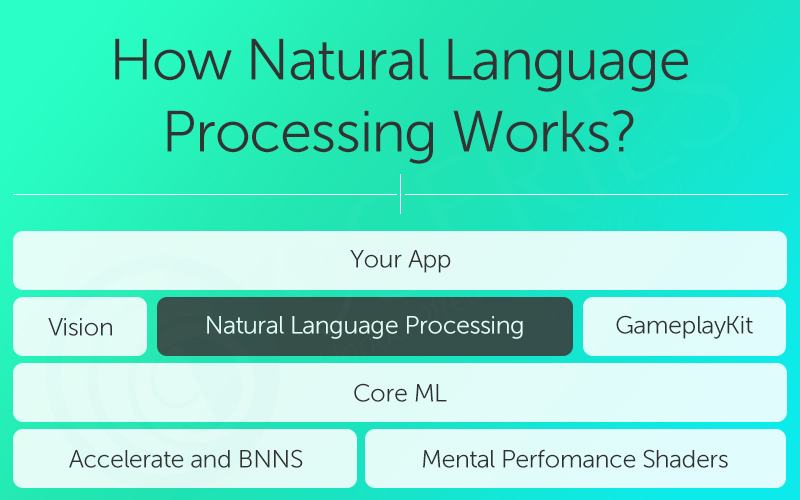
The Power of Natural Language Processing (NLP) in Today’s World
Natural Language Processing (NLP) is a branch of artificial intelligence that focuses on the interaction between computers and humans using natural language. This field has seen tremendous growth and advancement in recent years, revolutionizing various industries and applications.
One of the key areas where NLP is making a significant impact is in the field of communication. NLP technologies enable machines to understand, interpret, and generate human language, allowing for more natural and seamless interactions between humans and computers. This has led to the development of virtual assistants, chatbots, and other AI-powered tools that enhance communication efficiency and convenience.
In addition to communication, NLP is also being used in data analysis and information retrieval. By processing large volumes of text data quickly and accurately, NLP algorithms can extract valuable insights, identify patterns, and make predictions based on textual information. This has proven to be invaluable in fields such as healthcare, finance, marketing, and more.
Moreover, NLP plays a crucial role in language translation and sentiment analysis. With advanced NLP models like neural machine translation systems and sentiment analysis algorithms, language barriers can be overcome more easily, allowing for effective cross-cultural communication and understanding.
Overall, the power of NLP lies in its ability to bridge the gap between human language and machine understanding. As NLP technology continues to evolve and improve, we can expect to see even more innovative applications that enhance our daily lives and transform the way we interact with technology.
6 Essential Tips for Effective Natural Language Processing
- Preprocess text data by removing noise, such as special characters and punctuation.
- Tokenize the text into words or subwords to break down the input into manageable units.
- Remove stop words like ‘and’, ‘the’, ‘is’ that do not carry significant meaning.
- Lemmatize or stem words to reduce them to their base form for better analysis.
- Utilize word embeddings like Word2Vec or GloVe to represent words as dense vectors.
- Consider using pre-trained models like BERT or GPT for more advanced NLP tasks.
Preprocess text data by removing noise, such as special characters and punctuation.
When working with Natural Language Processing (NLP) tasks, a crucial tip is to preprocess text data by eliminating noise, such as special characters and punctuation. By removing these unnecessary elements from the text, NLP algorithms can focus on the actual content of the data, leading to more accurate analysis and better results. This preprocessing step helps in cleaning the text and preparing it for further processing, ensuring that the NLP model can effectively understand and interpret the language without being distracted by irrelevant symbols or characters.
Tokenize the text into words or subwords to break down the input into manageable units.
Tokenization is a fundamental step in Natural Language Processing (NLP) that involves breaking down a piece of text into individual words or subwords. By tokenizing the text, we can convert the input into manageable units that can be processed and analyzed more effectively by NLP algorithms. This process not only helps in understanding the structure of the text but also enables the extraction of meaningful insights and patterns from the data. Tokenization plays a crucial role in various NLP tasks, such as language modeling, sentiment analysis, and machine translation, by providing a structured representation of the input text for further processing and analysis.
Remove stop words like ‘and’, ‘the’, ‘is’ that do not carry significant meaning.
In Natural Language Processing (NLP), a common tip for improving text analysis is to remove stop words such as ‘and’, ‘the’, and ‘is’ that lack substantial meaning. By eliminating these frequently occurring but less informative words, NLP algorithms can focus on the more relevant and significant terms in the text, leading to more accurate and meaningful analysis results. This preprocessing step helps streamline the data and allows NLP models to extract key insights and patterns from the text more effectively.
Lemmatize or stem words to reduce them to their base form for better analysis.
Lemmatizing or stemming words is a crucial step in natural language processing (NLP) to reduce them to their base form, enabling more effective analysis. By transforming words into their root form, variations of the same word are consolidated, leading to improved accuracy and efficiency in tasks such as text mining, sentiment analysis, and information retrieval. This process helps in standardizing the vocabulary and simplifying the computational workload, ultimately enhancing the overall performance of NLP algorithms and models.
Utilize word embeddings like Word2Vec or GloVe to represent words as dense vectors.
By utilizing word embeddings such as Word2Vec or GloVe, words can be represented as dense vectors in natural language processing (NLP). These embeddings capture semantic relationships between words and enable machines to understand language in a more meaningful way. By converting words into numerical vectors, NLP models can perform tasks like text classification, sentiment analysis, and machine translation more effectively, leading to improved accuracy and efficiency in language processing tasks.
Consider using pre-trained models like BERT or GPT for more advanced NLP tasks.
When delving into more advanced Natural Language Processing (NLP) tasks, it is highly beneficial to consider utilizing pre-trained models such as BERT or GPT. These sophisticated models have been trained on vast amounts of text data and possess a deep understanding of language nuances, making them invaluable for tasks requiring complex language processing. By leveraging pre-trained models like BERT or GPT, NLP practitioners can enhance the accuracy and efficiency of their analyses, enabling them to tackle challenging NLP tasks with greater ease and effectiveness.