Natural Language Processing (NLP) Code: Transforming Words into Actionable Insights
In the realm of artificial intelligence and machine learning, Natural Language Processing (NLP) plays a crucial role in enabling computers to understand, interpret, and generate human language. NLP code serves as the backbone of various applications that rely on language processing, such as chatbots, sentiment analysis, language translation, and text summarization.
At its core, NLP code consists of algorithms and models designed to process and analyze textual data. These codes are built using programming languages like Python, Java, or C++, along with specialized libraries and frameworks such as NLTK (Natural Language Toolkit), spaCy, and TensorFlow. By leveraging these tools, developers can create powerful NLP applications that extract meaningful insights from unstructured text.
One common task performed by NLP code is text classification, where algorithms categorize text into predefined classes or labels based on their content. Sentiment analysis is another popular application of NLP code, which involves determining the emotional tone of a piece of text – whether it is positive, negative, or neutral.
Named Entity Recognition (NER) is yet another important function of NLP code that identifies and classifies entities mentioned in text – such as names of people, organizations, locations, dates, and more. This capability is essential for information extraction tasks like extracting key information from news articles or social media posts.
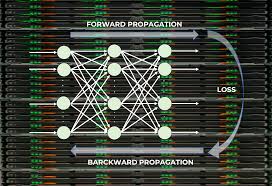
Furthermore, NLP code enables the development of chatbots that can engage in natural conversations with users by understanding their queries and providing relevant responses. By incorporating machine learning techniques like deep learning and recurrent neural networks into NLP code, developers can enhance the accuracy and efficiency of language processing tasks.
In conclusion, NLP code serves as a powerful tool for unlocking the potential of textual data by transforming words into actionable insights. As advancements in artificial intelligence continue to evolve rapidly, the role of NLP in driving innovation across various industries will only grow stronger.
5 Essential Tips for Enhancing Your NLP Code
- Preprocess text data by removing stopwords, punctuation, and special characters.
- Tokenize the text to convert it into a list of words or subwords for further processing.
- Use word embeddings like Word2Vec or GloVe to represent words as dense vectors for NLP tasks.
- Implement techniques like TF-IDF or Bag of Words for text vectorization before training machine learning models.
- Consider using pre-trained language models like BERT or GPT-3 for advanced NLP tasks to leverage transfer learning.
Preprocess text data by removing stopwords, punctuation, and special characters.
To enhance the effectiveness of NLP code, it is crucial to preprocess text data by removing stopwords, punctuation, and special characters. By eliminating these irrelevant elements from the text, the focus shifts to the essential words and phrases, improving the accuracy of language processing tasks such as sentiment analysis, text classification, and named entity recognition. This preprocessing step not only streamlines the data but also helps in extracting meaningful insights from the text, leading to more precise and efficient NLP outcomes.
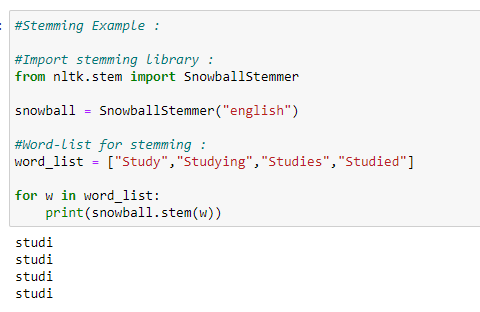
Tokenize the text to convert it into a list of words or subwords for further processing.
To enhance the efficiency and accuracy of NLP code, a crucial tip is to tokenize the text, breaking it down into a list of individual words or subwords. By tokenizing the text, developers can segment the input data into smaller units, making it easier to analyze and process. This step not only simplifies the handling of textual information but also lays the foundation for various NLP tasks such as text classification, sentiment analysis, and entity recognition. Tokenization is an essential preprocessing step that paves the way for extracting meaningful insights from unstructured text data in a structured and organized manner.
Use word embeddings like Word2Vec or GloVe to represent words as dense vectors for NLP tasks.
Utilizing word embeddings such as Word2Vec or GloVe is a fundamental tip in NLP code development. These techniques enable words to be represented as dense vectors in a continuous vector space, capturing semantic relationships and contextual information. By leveraging word embeddings, NLP models can better understand the meaning of words based on their usage in context, leading to improved performance in tasks like sentiment analysis, text classification, and language translation. Incorporating word embeddings into NLP code enhances the efficiency and accuracy of language processing tasks by providing a more nuanced representation of words that goes beyond traditional one-hot encoding methods.
Implement techniques like TF-IDF or Bag of Words for text vectorization before training machine learning models.
To enhance the effectiveness of NLP code in training machine learning models, it is recommended to implement techniques such as TF-IDF (Term Frequency-Inverse Document Frequency) or Bag of Words for text vectorization. These methods play a crucial role in converting textual data into numerical representations that can be processed by machine learning algorithms. By utilizing TF-IDF or Bag of Words, the model can capture the importance of words within the context of a document, enabling more accurate and meaningful analysis of text data. This preprocessing step is essential for improving the performance and efficiency of NLP models in tasks such as sentiment analysis, text classification, and information retrieval.
Consider using pre-trained language models like BERT or GPT-3 for advanced NLP tasks to leverage transfer learning.
When working on advanced NLP tasks, it is highly beneficial to consider utilizing pre-trained language models such as BERT or GPT-3. These models have been trained on vast amounts of text data and have learned intricate language patterns, making them incredibly powerful for a wide range of natural language processing tasks. By leveraging transfer learning with pre-trained models like BERT or GPT-3, developers can significantly enhance the performance and efficiency of their NLP code, enabling them to tackle complex language processing challenges with greater accuracy and speed.