Deep Neural Networks in Machine Learning
In recent years, deep neural networks (DNNs) have become a cornerstone of machine learning, driving advancements in various fields such as computer vision, natural language processing, and more. But what exactly are deep neural networks and why are they so pivotal?
Understanding Deep Neural Networks
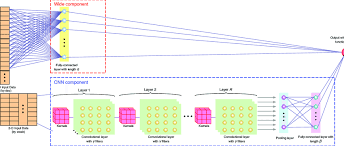
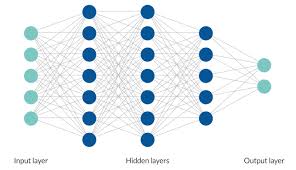
A deep neural network is a type of artificial neural network (ANN) with multiple layers between the input and output layers. These intermediate layers, often referred to as hidden layers, allow the network to learn complex patterns and representations from data.
The architecture of a DNN is inspired by the human brain’s structure, where neurons are interconnected and work together to process information. Each layer in a DNN consists of nodes (or neurons), each performing a simple computation. The power of DNNs lies in their ability to combine these computations across many layers to model intricate relationships within data.
The Role of Deep Learning
Deep learning is a subset of machine learning that focuses on using DNNs for tasks that require understanding high-dimensional data. Unlike traditional machine learning algorithms that rely heavily on feature engineering, deep learning models can automatically discover features from raw data.
This capability makes deep learning particularly effective for tasks like image recognition, speech processing, and autonomous driving systems. For instance, convolutional neural networks (CNNs), a type of DNN specialized for grid-like data such as images, have revolutionized computer vision by achieving near-human accuracy in image classification tasks.
Training Deep Neural Networks
Training a deep neural network involves adjusting its weights through an optimization process known as backpropagation. During training, the network learns by minimizing the difference between its predictions and actual outcomes using a loss function.
This process requires large amounts of labeled data and computational resources due to the complexity and depth of these networks. Advances in hardware technology, particularly GPUs and TPUs, have significantly accelerated the training process for DNNs.
Applications and Impact
The impact of deep neural networks extends across various industries:
- Healthcare: DNNs are used for disease diagnosis through medical imaging analysis.
- Finance: They help in fraud detection by identifying unusual patterns in transaction data.
- Entertainment: Streaming services use them for content recommendation systems.
The Future of Deep Neural Networks
The future holds exciting possibilities for deep neural networks as researchers continue to push boundaries with new architectures like transformers and generative adversarial networks (GANs). These innovations promise even more sophisticated models capable of understanding context better than ever before.
As we advance further into the era of artificial intelligence, deep neural networks will undoubtedly play an integral role in shaping technologies that enhance our lives and solve complex global challenges.
8 Essential Tips for Optimizing Deep Neural Networks in Machine Learning
- Choose the appropriate activation function for each layer.
- Regularize your model to prevent overfitting.
- Normalize input data to speed up training and improve performance.
- Use dropout layers to reduce overfitting in deep neural networks.
- Monitor and visualize the training process to identify issues early on.
- Experiment with different network architectures to find the most suitable one for your problem.
- Fine-tune hyperparameters such as learning rate, batch size, and number of epochs for optimal performance.
- Consider using pre-trained models or transfer learning to leverage existing knowledge.
Choose the appropriate activation function for each layer.
In deep neural networks for machine learning, selecting the right activation function for each layer is crucial for the network’s performance. Different activation functions serve different purposes, such as introducing non-linearities or controlling the output range of neurons. By choosing the appropriate activation function for each layer, developers can ensure that the network can effectively learn complex patterns and relationships within the data. This thoughtful selection process plays a significant role in optimizing the network’s training process and overall accuracy in solving various tasks.
Regularize your model to prevent overfitting.
Regularizing your model is a crucial tip in deep neural network machine learning to prevent overfitting. Overfitting occurs when a model learns the training data too well, capturing noise and irrelevant patterns that do not generalize to new, unseen data. By applying regularization techniques such as L1 or L2 regularization, dropout, or early stopping, you can impose constraints on the model’s complexity and prevent it from memorizing the training data. Regularization helps strike a balance between fitting the training data accurately and maintaining generalization performance on unseen data, ultimately improving the robustness and reliability of your deep neural network model.
Normalize input data to speed up training and improve performance.
Normalizing input data is a crucial tip in deep neural network training for machine learning. By standardizing the scale of input features, the network can learn more efficiently and converge faster during training. Normalization helps prevent large variations in input values that can hinder the optimization process, leading to improved model performance and accuracy. Overall, this simple yet effective technique not only speeds up training but also enhances the overall effectiveness of deep neural networks in handling complex datasets.
Use dropout layers to reduce overfitting in deep neural networks.
To address overfitting in deep neural networks, a useful tip is to incorporate dropout layers. Dropout is a regularization technique that helps prevent complex models from memorizing noise in the training data by randomly “dropping out” (deactivating) a fraction of neurons during each training iteration. This process encourages the network to learn more robust and generalizable features, ultimately improving its performance on unseen data. By implementing dropout layers strategically within the network architecture, machine learning practitioners can effectively combat overfitting and enhance the model’s ability to generalize to new data.
Monitor and visualize the training process to identify issues early on.
Monitoring and visualizing the training process of deep neural networks in machine learning is a crucial tip to identify issues early on. By keeping a close eye on metrics such as loss and accuracy during training, developers can quickly detect any anomalies or performance bottlenecks. Visualizing these metrics through tools like TensorBoard or custom plots provides valuable insights into the network’s behavior, enabling timely adjustments to hyperparameters or model architecture. This proactive approach not only helps in troubleshooting potential problems but also enhances the overall efficiency and effectiveness of the training process.
Experiment with different network architectures to find the most suitable one for your problem.
To optimize the performance of deep neural networks in machine learning, it is crucial to experiment with various network architectures to identify the most suitable one for a specific problem. By exploring different configurations of layers, nodes, and connections within the network, researchers and practitioners can fine-tune the model to achieve better accuracy and efficiency in solving complex tasks. This iterative process of testing and refining network architectures plays a key role in maximizing the potential of deep learning algorithms for diverse applications across industries.
Fine-tune hyperparameters such as learning rate, batch size, and number of epochs for optimal performance.
To maximize the performance of a deep neural network in machine learning, it is crucial to fine-tune key hyperparameters such as the learning rate, batch size, and number of epochs. Adjusting these parameters can significantly impact the model’s training process and overall accuracy. By carefully optimizing the learning rate to control the step size during gradient descent, selecting an appropriate batch size for efficient computation, and determining the optimal number of epochs for convergence without overfitting, researchers and practitioners can achieve optimal performance and enhance the effectiveness of their deep neural network models.
Consider using pre-trained models or transfer learning to leverage existing knowledge.
Consider using pre-trained models or transfer learning to leverage existing knowledge in deep neural network applications within machine learning. By utilizing pre-trained models, which have been trained on large datasets for specific tasks, you can benefit from the learned features and weights, saving time and computational resources. Transfer learning allows you to adapt these pre-trained models to new tasks or datasets, fine-tuning them to achieve better performance with less data. This approach not only accelerates the training process but also enhances the overall efficiency and effectiveness of your deep neural network models.