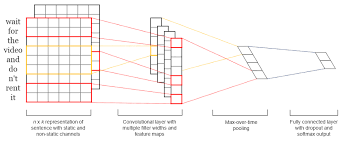
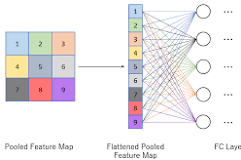
Image segmentation using Convolutional Neural Networks (CNN) is a powerful technique in the field of computer vision that allows for precise identification and delineation of objects within an image. CNNs have revolutionized the way we approach image analysis tasks, providing accurate and efficient solutions for tasks such as object detection, image classification, and semantic segmentation.
Segmentation is the process of partitioning an image into multiple segments or regions based on certain characteristics, such as color, texture, or shape. Image segmentation using CNN involves training a neural network to learn and recognize patterns within an image that correspond to different objects or regions of interest.
CNNs are well-suited for image segmentation tasks due to their ability to automatically extract features from images at different spatial scales. By using convolutional layers, pooling layers, and fully connected layers, CNNs can effectively capture hierarchical patterns in images and make accurate predictions about the boundaries of objects within an image.
One popular approach to image segmentation using CNN is the U-Net architecture, which consists of an encoder-decoder network with skip connections. The encoder part of the network captures high-level features from the input image, while the decoder part reconstructs the segmented output based on these features. Skip connections help preserve spatial information and improve segmentation accuracy.
Image segmentation using CNN has numerous applications across various industries, including medical imaging, autonomous driving, satellite imagery analysis, and more. In medical imaging, CNN-based segmentation techniques are used for tumor detection, organ localization, and disease diagnosis. In autonomous driving systems, CNNs are employed to detect pedestrians, vehicles, and road signs for safe navigation.
In conclusion, image segmentation using Convolutional Neural Networks is a cutting-edge technology that enables precise identification and delineation of objects within images. With its ability to automatically learn features from images and make accurate predictions about object boundaries, CNN-based segmentation has become a valuable tool in computer vision research and applications.
9 Essential Tips for Effective Image Segmentation with CNNs
- 1. Preprocess your images by resizing them to a fixed size before feeding them into the CNN.
- 2. Use data augmentation techniques like rotation, flipping, and scaling to increase the diversity of your training dataset.
- 3. Choose an appropriate loss function such as cross-entropy or Dice coefficient for image segmentation tasks.
- 4. Experiment with different network architectures like U-Net, FCN, or DeepLab to find the best model for your specific task.
- 5. Fine-tune pre-trained CNN models on large datasets like ImageNet before training on your specific segmentation dataset.
- 6. Utilize techniques like batch normalization and dropout to prevent overfitting during training.
- 7. Monitor the performance of your model using metrics like Intersection over Union (IoU) and Mean Intersection over Union (mIoU).
- 8. Consider using transfer learning by leveraging features learned from a related task or domain for improved segmentation performance.
- 9. Post-process the output masks generated by the CNN using techniques like morphological operations to improve segmentation accuracy.
1. Preprocess your images by resizing them to a fixed size before feeding them into the CNN.
To improve the efficiency and accuracy of image segmentation using CNN, it is recommended to preprocess your images by resizing them to a fixed size before feeding them into the neural network. By resizing the images to a consistent dimension, you ensure that the CNN receives uniform input data, which can help in optimizing the training process and enhancing the segmentation results. This preprocessing step can also help in reducing computational complexity and memory usage during training, making the segmentation process more streamlined and effective.
2. Use data augmentation techniques like rotation, flipping, and scaling to increase the diversity of your training dataset.
To enhance the effectiveness of image segmentation using CNN, it is recommended to implement data augmentation techniques such as rotation, flipping, and scaling. By applying these techniques, the diversity of the training dataset can be increased, allowing the neural network to learn a wider range of patterns and variations present in the images. Rotation helps the model generalize better to different orientations of objects, flipping aids in capturing symmetrical features, and scaling assists in recognizing objects at various sizes. Overall, incorporating data augmentation methods like rotation, flipping, and scaling can improve the robustness and accuracy of CNN-based image segmentation models.
3. Choose an appropriate loss function such as cross-entropy or Dice coefficient for image segmentation tasks.
When performing image segmentation using Convolutional Neural Networks, it is crucial to select the right loss function to optimize the model’s performance. Options like cross-entropy or Dice coefficient are commonly used for image segmentation tasks due to their effectiveness in measuring the dissimilarity between predicted and ground truth segmentation masks. Cross-entropy loss is suitable for pixel-wise classification tasks, while the Dice coefficient is known for handling class imbalance issues in segmentation. By choosing an appropriate loss function, such as cross-entropy or Dice coefficient, practitioners can enhance the accuracy and robustness of their CNN models for image segmentation applications.
4. Experiment with different network architectures like U-Net, FCN, or DeepLab to find the best model for your specific task.
To optimize image segmentation using CNN, it is advisable to experiment with various network architectures such as U-Net, FCN, or DeepLab to determine the most suitable model for your specific task. Each architecture has its strengths and weaknesses, and by testing different models, you can identify the one that best aligns with the requirements of your project. U-Net’s encoder-decoder structure with skip connections is ideal for preserving spatial information, while FCN’s fully convolutional design enables efficient end-to-end learning. DeepLab, on the other hand, incorporates atrous convolutions for multi-scale feature extraction. By exploring these different architectures, you can enhance the accuracy and performance of your image segmentation tasks using CNN technology.
5. Fine-tune pre-trained CNN models on large datasets like ImageNet before training on your specific segmentation dataset.
To enhance the performance of image segmentation using CNN, a valuable tip is to fine-tune pre-trained CNN models on extensive datasets like ImageNet before training on your specific segmentation dataset. By leveraging pre-trained models that have already learned rich features from a vast dataset like ImageNet, you can benefit from their generalization capabilities and adapt them to your specific segmentation task. Fine-tuning allows the model to adjust its parameters and learn task-specific features more efficiently, leading to improved accuracy and robustness in segmenting objects within images.
6. Utilize techniques like batch normalization and dropout to prevent overfitting during training.
To enhance the performance of image segmentation using Convolutional Neural Networks, it is crucial to implement techniques like batch normalization and dropout during training. Batch normalization helps stabilize and accelerate the training process by normalizing the input of each layer, reducing internal covariate shift, and improving the network’s generalization ability. Dropout, on the other hand, prevents overfitting by randomly deactivating a certain percentage of neurons during each training iteration, forcing the network to learn more robust features and reducing reliance on specific neurons. By incorporating these techniques into the training process, one can effectively prevent overfitting and improve the overall performance of CNN-based image segmentation models.
7. Monitor the performance of your model using metrics like Intersection over Union (IoU) and Mean Intersection over Union (mIoU).
To ensure the effectiveness and accuracy of your image segmentation model using Convolutional Neural Networks, it is crucial to monitor its performance using metrics such as Intersection over Union (IoU) and Mean Intersection over Union (mIoU). These metrics provide valuable insights into how well your model is able to accurately segment objects within images by measuring the overlap between predicted and ground truth segmentation masks. By regularly evaluating your model’s performance with IoU and mIoU metrics, you can identify areas for improvement, fine-tune your training process, and ultimately enhance the quality of your segmentation results.
8. Consider using transfer learning by leveraging features learned from a related task or domain for improved segmentation performance.
When working on image segmentation using CNN, a valuable tip to enhance performance is to consider employing transfer learning. By leveraging features learned from a related task or domain, transfer learning can significantly improve segmentation accuracy and efficiency. This approach allows the model to benefit from pre-existing knowledge and patterns captured in the features of a different but related task, ultimately enhancing the segmentation performance by building upon this foundation.
9. Post-process the output masks generated by the CNN using techniques like morphological operations to improve segmentation accuracy.
To enhance the accuracy of image segmentation using CNN, a valuable tip is to post-process the output masks generated by the network with techniques like morphological operations. By applying morphological operations such as dilation, erosion, and opening/closing, it is possible to refine and improve the quality of the segmentation results. These operations help to smooth out rough edges, fill in small gaps, and remove noise from the segmented regions, ultimately leading to more precise and reliable object delineation within images. Integrating post-processing techniques into the workflow can significantly enhance the overall performance of CNN-based image segmentation systems.