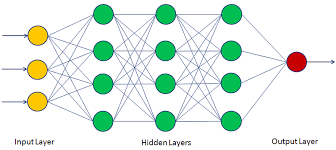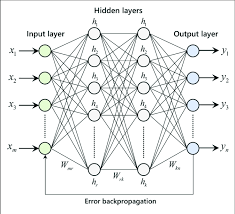
A multilayer perceptron (MLP) is a type of artificial neural network that consists of multiple layers of nodes, each connected to the next layer. MLPs are widely used in machine learning for various tasks such as classification, regression, and pattern recognition.
Let’s consider a simple example to illustrate how a multilayer perceptron works. Suppose we have a dataset of images of handwritten digits (0-9) and we want to build a model that can classify these digits correctly.
The input layer of the MLP will consist of nodes representing the pixel values of the images. Each node in the input layer corresponds to a single pixel in the image. The number of nodes in the input layer will depend on the size of the images.
Next, we have one or more hidden layers in the MLP. Each node in a hidden layer is connected to every node in the previous layer and has its own set of weights and biases. These weights and biases are adjusted during training to optimize the performance of the network.
Finally, we have the output layer, which consists of nodes representing the possible classes (in this case, digits 0-9). The output layer uses an activation function such as softmax to produce probabilities for each class, indicating the likelihood that an input image belongs to that class.
During training, the MLP learns by adjusting its weights and biases based on feedback from comparing its predictions with the actual labels in the training data. This process is known as backpropagation, where errors are propagated backward through the network to update the parameters and improve performance.
Once trained, the MLP can be used to predict the class of new unseen images by passing them through the network and interpreting the output probabilities from the final layer.
In conclusion, multilayer perceptrons are powerful tools for solving complex machine learning problems by leveraging multiple layers of interconnected nodes. By understanding how an MLP processes data and makes predictions, we can harness its capabilities to tackle a wide range of real-world challenges.
6 Essential Tips for Optimizing Your Multilayer Perceptron Model
- Ensure proper data preprocessing such as normalization and encoding categorical variables.
- Choose an appropriate activation function for the hidden layers like ReLU or tanh.
- Experiment with different numbers of hidden layers and neurons to find the optimal architecture.
- Use techniques like dropout regularization to prevent overfitting.
- Monitor the training process by tracking metrics like loss and accuracy.
- Fine-tune hyperparameters such as learning rate and batch size for better performance.
Ensure proper data preprocessing such as normalization and encoding categorical variables.
To maximize the effectiveness of a multilayer perceptron example, it is crucial to prioritize proper data preprocessing techniques. This includes steps like normalization, which scales the input data to a standard range, and encoding categorical variables, which converts non-numeric data into a numerical format that the model can interpret. By ensuring that the data is preprocessed correctly before training the multilayer perceptron, we can enhance its performance and accuracy in handling complex tasks such as classification or regression.
Choose an appropriate activation function for the hidden layers like ReLU or tanh.
When working with a multilayer perceptron example, it is crucial to choose an appropriate activation function for the hidden layers, such as ReLU (Rectified Linear Unit) or tanh (Hyperbolic Tangent). These activation functions play a significant role in determining the non-linearity and learning capabilities of the neural network. ReLU is known for its simplicity and effectiveness in combating the vanishing gradient problem, while tanh can introduce non-linearity and help capture complex patterns in the data. By selecting the right activation function for the hidden layers, we can enhance the performance and efficiency of the multilayer perceptron model in handling diverse datasets and tasks effectively.
Experiment with different numbers of hidden layers and neurons to find the optimal architecture.
To optimize the performance of a multilayer perceptron, it is essential to experiment with varying numbers of hidden layers and neurons to determine the most effective architecture. By adjusting the complexity of the network through the number of layers and neurons, researchers and developers can fine-tune the model to achieve optimal results for a specific task or dataset. This process of exploration and iteration allows for the discovery of the most suitable architecture that maximizes accuracy and efficiency in neural network operations.
Use techniques like dropout regularization to prevent overfitting.
When working with a multilayer perceptron example, it is crucial to employ techniques like dropout regularization to prevent overfitting. Overfitting occurs when a model learns the training data too well, to the point that it performs poorly on unseen data. Dropout regularization helps combat overfitting by randomly dropping out (setting to zero) a percentage of nodes in the network during training. This technique encourages the network to learn more robust and generalizable features, leading to better performance on new data. By incorporating dropout regularization into the training process, we can improve the overall effectiveness and reliability of our multilayer perceptron models.
Monitor the training process by tracking metrics like loss and accuracy.
Monitoring the training process of a multilayer perceptron example is crucial for assessing its performance and making necessary adjustments. By tracking metrics such as loss and accuracy throughout the training phase, you can gain insights into how well the model is learning from the data. The loss metric indicates how well the model is minimizing errors during training, while accuracy provides a measure of how accurately the model is predicting outcomes. Monitoring these metrics allows you to identify potential issues, fine-tune parameters, and optimize the model for better results.
Fine-tune hyperparameters such as learning rate and batch size for better performance.
To enhance the performance of a multilayer perceptron example, it is crucial to fine-tune hyperparameters like the learning rate and batch size. The learning rate determines how much the model adjusts its weights during training, impacting the speed and quality of convergence. Adjusting this parameter can help prevent underfitting or overfitting of the data. Similarly, optimizing the batch size, which determines the number of samples processed before updating the model’s parameters, can lead to more stable training and improved generalization on unseen data. By carefully adjusting these hyperparameters, we can ensure that our multilayer perceptron model achieves optimal performance and accuracy in its predictions.