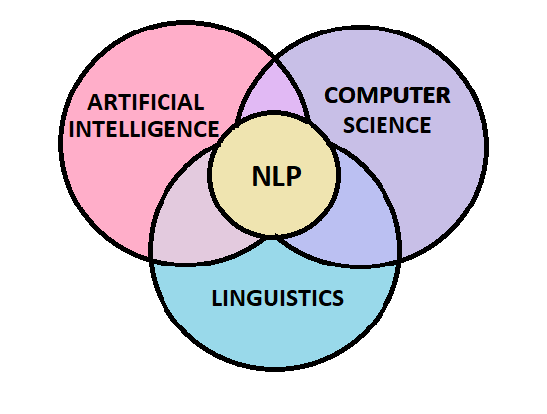
Neural networks are a powerful class of machine learning algorithms inspired by the structure and function of the human brain. They are widely used in various fields, including image recognition, natural language processing, and predictive analytics.
One common example of a neural network algorithm is the feedforward neural network. This type of neural network consists of an input layer, one or more hidden layers, and an output layer. Each layer is made up of interconnected nodes, also known as neurons, which simulate the function of biological neurons in the brain.
Here is a simple example to illustrate how a feedforward neural network works:
Step 1: Input Layer
The input layer receives the raw data or features that need to be processed. Each input node corresponds to a feature or attribute of the data being fed into the network.
Step 2: Hidden Layers
The hidden layers perform complex computations on the input data through weighted connections between nodes. Each connection has an associated weight that determines the strength of the relationship between nodes.
Step 3: Activation Function
At each node in the hidden layers and output layer, an activation function is applied to introduce non-linearity into the model. This allows the neural network to learn complex patterns and relationships in the data.
Step 4: Output Layer
The output layer produces the final result or prediction based on the processed input data. The number of nodes in this layer depends on the type of problem being solved (e.g., classification or regression).
Step 5: Training
During training, the neural network adjusts its weights and biases using optimization algorithms like gradient descent to minimize prediction errors. This process involves forward propagation (computing predictions) and backpropagation (updating weights based on prediction errors).
Step 6: Prediction
Once trained, the neural network can make predictions on new, unseen data by passing it through the network architecture and computing outputs based on learned patterns.
In conclusion, neural networks are versatile algorithms that can learn complex patterns from data and make accurate predictions. By understanding how they work and their components like activation functions and hidden layers, we can leverage their power for various machine learning tasks.
6 Essential Tips for Optimizing Neural Network Algorithms: From Basics to Advanced Techniques
- Start with a simple neural network architecture before trying more complex ones.
- Normalize input data to ensure faster convergence and better performance.
- Use appropriate activation functions for hidden layers, such as ReLU or sigmoid.
- Regularize your model using techniques like L1 or L2 regularization to prevent overfitting.
- Monitor the training process by visualizing metrics like loss and accuracy to make informed decisions.
- Experiment with hyperparameters like learning rate and batch size to optimize model performance.
Start with a simple neural network architecture before trying more complex ones.
Starting with a simple neural network architecture before attempting more complex ones is a wise tip for beginners in machine learning. By beginning with a basic structure, such as a feedforward neural network with one hidden layer, individuals can grasp the fundamental concepts of neural networks, including input layers, hidden layers, activation functions, and output layers. This approach allows for a gradual understanding of how neural networks process data and make predictions, laying a strong foundation for tackling more advanced architectures in the future. Mastering the basics first ensures a solid comprehension of neural network principles and sets the stage for successful exploration of more intricate models down the line.
Normalize input data to ensure faster convergence and better performance.
Normalizing input data is a crucial tip when working with neural network algorithms to ensure faster convergence and improved performance. By scaling the input data to a standardized range, such as between 0 and 1 or -1 and 1, we can prevent certain features from dominating the learning process and causing slow convergence or model instability. Normalization helps the neural network to learn more efficiently by ensuring that all input variables contribute equally to the training process, leading to better generalization and overall performance of the model.
Use appropriate activation functions for hidden layers, such as ReLU or sigmoid.
When implementing a neural network algorithm example, it is crucial to use appropriate activation functions for hidden layers to ensure the model’s effectiveness. Popular choices include Rectified Linear Unit (ReLU) and sigmoid functions. ReLU is commonly used for hidden layers as it helps address the vanishing gradient problem and accelerates convergence during training. On the other hand, the sigmoid function is often employed in binary classification tasks due to its ability to squash output values between 0 and 1. By selecting the right activation functions for hidden layers, such as ReLU or sigmoid, one can enhance the neural network’s performance and optimize its learning capabilities.
Regularize your model using techniques like L1 or L2 regularization to prevent overfitting.
To enhance the performance and generalization of your neural network model, it is crucial to apply regularization techniques such as L1 or L2 regularization. These methods help prevent overfitting by adding a penalty term to the loss function, discouraging overly complex models that may perform well on training data but fail to generalize to unseen data. By regularizing your model, you can achieve a balance between fitting the training data effectively and avoiding excessive complexity, ultimately improving the model’s ability to make accurate predictions on new data.
Monitor the training process by visualizing metrics like loss and accuracy to make informed decisions.
Monitoring the training process of a neural network algorithm is crucial for optimizing its performance. By visualizing key metrics such as loss and accuracy during training, developers can gain valuable insights into how well the model is learning and making predictions. Tracking these metrics allows for informed decisions to be made regarding adjustments to the network architecture, hyperparameters, or training data. This iterative process of monitoring and refining the model based on performance metrics ultimately leads to a more effective and accurate neural network algorithm.
Experiment with hyperparameters like learning rate and batch size to optimize model performance.
To optimize the performance of a neural network algorithm example, it is crucial to experiment with hyperparameters such as learning rate and batch size. The learning rate determines how quickly the model adapts to the training data, while the batch size affects how many samples are processed before updating the model’s parameters. By tuning these hyperparameters through experimentation, developers can fine-tune the neural network to achieve better accuracy and faster convergence during training. Adjusting these settings can significantly impact the model’s performance and ultimately lead to more effective and efficient results in various machine learning tasks.