Vanilla Recurrent Neural Network: Understanding the Basics
Recurrent Neural Networks (RNNs) have revolutionized the field of artificial intelligence, particularly in the realm of natural language processing and sequential data analysis. Among the various types of RNN architectures, the Vanilla Recurrent Neural Network stands out as a fundamental model that forms the basis for more advanced variants.
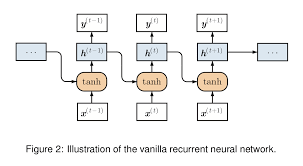
At its core, a Vanilla RNN is designed to process sequential data by maintaining a hidden state that captures information from previous time steps. This hidden state serves as a memory element that allows the network to retain context and dependencies across different parts of the input sequence.
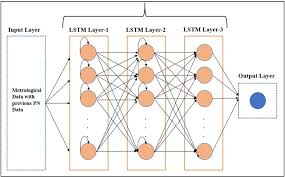
The key characteristic of a Vanilla RNN is its simple structure, consisting of a single layer of recurrent units connected in a chain-like fashion. Each unit takes an input along with the hidden state from the previous time step, processes this information through activation functions, and produces an output along with an updated hidden state.
Despite its simplicity, Vanilla RNNs have proven to be effective in tasks such as language modeling, speech recognition, and time series prediction. However, they are also known to suffer from issues like vanishing gradients and difficulty in capturing long-term dependencies due to their inherent architecture.
To address these limitations, more advanced RNN variants like Long Short-Term Memory (LSTM) networks and Gated Recurrent Units (GRUs) have been developed. These models incorporate sophisticated mechanisms to better control information flow and memory retention within the network.
In conclusion, while Vanilla Recurrent Neural Networks serve as a foundational concept in sequential data processing, their straightforward architecture may not always be suitable for capturing complex patterns in long sequences. Understanding the strengths and limitations of Vanilla RNNs can guide researchers and practitioners in choosing appropriate models for their specific applications.
Understanding Vanilla Recurrent Neural Networks: Key Concepts and Limitations
- What is vanilla model in machine learning?
- What is a vanilla recurrent neural network?
- What is the difference between RNN and vanilla RNN?
- What are the main limitations of vanilla RNN?
- What are the limitations of vanilla RNN?
What is vanilla model in machine learning?
In the context of machine learning, the term “vanilla model” refers to a basic or standard version of a particular algorithm or neural network architecture without any additional complex modifications or enhancements. When discussing Vanilla Recurrent Neural Networks, for example, it denotes a simple RNN structure with a single layer of recurrent units connected sequentially. While vanilla models are straightforward and easy to understand, they may lack the advanced features and capabilities found in more sophisticated variants. Researchers often use vanilla models as a starting point to establish a baseline performance before exploring more intricate models with improved functionalities.
What is a vanilla recurrent neural network?
A Vanilla Recurrent Neural Network, often referred to as a basic form of RNN, is a fundamental architecture used in the realm of artificial intelligence and deep learning. It is designed to process sequential data by incorporating a hidden state that retains information from previous time steps. This hidden state acts as a memory component, enabling the network to capture dependencies and context across the input sequence. Despite its simplicity compared to more advanced RNN variants, Vanilla RNNs play a crucial role in tasks such as language modeling, time series analysis, and speech recognition. Understanding the concept of a Vanilla Recurrent Neural Network is essential for grasping the foundational principles of sequential data processing in machine learning.
What is the difference between RNN and vanilla RNN?
When comparing RNN and vanilla RNN, it is important to understand that vanilla RNN is a specific type of Recurrent Neural Network (RNN). The term “vanilla RNN” is often used to refer to the basic, traditional form of RNN without any additional complexities or modifications, such as Long Short-Term Memory (LSTM) units or Gated Recurrent Units (GRUs). In essence, vanilla RNNs have a simple architecture with a single layer of recurrent units that process sequential data by maintaining a hidden state. On the other hand, RNN is a broader category that encompasses various types of recurrent neural network architectures, including vanilla RNNs as well as more advanced variants. The main difference lies in the complexity and capabilities of the models, with vanilla RNN being a foundational and straightforward form of RNN, while RNN refers to the general concept of neural networks designed to handle sequential data.
What are the main limitations of vanilla RNN?
One of the most frequently asked questions about Vanilla Recurrent Neural Networks revolves around their main limitations. Despite their effectiveness in processing sequential data, Vanilla RNNs are known to face challenges such as vanishing gradients and difficulty in capturing long-term dependencies. The vanishing gradient problem occurs when gradients become extremely small during training, leading to slow learning or even stagnation. Additionally, Vanilla RNNs struggle to retain information over long sequences, which can hinder their ability to capture complex patterns and dependencies that span across multiple time steps. These limitations have prompted the development of more advanced RNN architectures, such as LSTM and GRU networks, which address these issues through specialized gating mechanisms and memory cells.
What are the limitations of vanilla RNN?
One frequently asked question regarding Vanilla Recurrent Neural Networks is about their limitations. One major limitation of Vanilla RNNs is the issue of vanishing gradients, where gradients become extremely small as they are backpropagated through time. This phenomenon makes it challenging for the network to learn long-range dependencies effectively, hindering its ability to capture information from earlier time steps. Additionally, Vanilla RNNs struggle with retaining memory over extended sequences, leading to difficulties in processing and understanding complex patterns in data that span a significant number of time steps. These limitations have prompted the development of more advanced RNN architectures, such as LSTMs and GRUs, which address these issues and offer improved performance in capturing long-term dependencies in sequential data.