Exploring Multilayer Perceptron with PyTorch
Artificial Neural Networks (ANNs) have revolutionized the field of machine learning, and one popular type of ANN is the Multilayer Perceptron (MLP). In this article, we delve into understanding and implementing MLP using PyTorch, a powerful open-source machine learning library.
What is a Multilayer Perceptron?
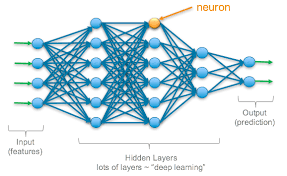
A Multilayer Perceptron is a type of feedforward neural network composed of multiple layers of nodes, each connected to the next layer. It consists of an input layer, one or more hidden layers, and an output layer. The nodes in each layer perform weighted summations and apply activation functions to produce output.
Implementing MLP with PyTorch
PyTorch provides a user-friendly interface for building neural networks, including MLPs. By utilizing PyTorch’s tensor operations and automatic differentiation capabilities, implementing an MLP becomes straightforward.
Here is a simple example code snippet demonstrating how to create an MLP using PyTorch:
import torch
import torch.nn as nn
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# Instantiate the MLP model
model = MLP()
Training and Evaluating the MLP
Once the MLP model is defined, it can be trained on a dataset using techniques like backpropagation and stochastic gradient descent. PyTorch simplifies this process by providing built-in optimization algorithms and loss functions.
To train the model on a dataset and evaluate its performance, you can use the following code snippet as a reference:
# Define loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# Training loop
for epoch in range(num_epochs):
# Forward pass
outputs = model(inputs)
loss = criterion(outputs, labels)
# Backward pass and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
Conclusion
In conclusion, exploring Multilayer Perceptrons with PyTorch opens up a world of possibilities for building sophisticated neural networks. By leveraging PyTorch’s flexibility and efficiency, developers can easily experiment with different architectures and train models for various tasks.
7 Essential Tips for Building Multilayer Perceptrons with PyTorch
- Define the architecture of the multilayer perceptron using torch.nn.Module class in PyTorch.
- Use torch.nn.Sequential to build a sequential model by stacking layers one after another.
- Choose an appropriate activation function for each layer such as ReLU, Sigmoid, or Tanh.
- Initialize the weights of the model properly to prevent vanishing or exploding gradients.
- Split your dataset into training and validation sets to evaluate the performance of your MLP.
- Utilize techniques like dropout regularization to prevent overfitting in your MLP model.
- Experiment with different hyperparameters like learning rate, batch size, and number of epochs for better performance.
Define the architecture of the multilayer perceptron using torch.nn.Module class in PyTorch.
To define the architecture of a multilayer perceptron in PyTorch, developers can utilize the torch.nn.Module class, which serves as the base class for all neural network modules in PyTorch. By subclassing this class and implementing the necessary forward method, users can specify the structure of their MLP model, including the number of layers, activation functions, and connections between nodes. This approach not only streamlines the process of creating neural networks but also allows for easy customization and experimentation with different architectures to achieve optimal performance in various machine learning tasks.
Use torch.nn.Sequential to build a sequential model by stacking layers one after another.
When working with Multilayer Perceptron in PyTorch, a useful tip is to utilize torch.nn.Sequential to construct a sequential model by stacking layers one after another. This approach simplifies the process of defining the neural network architecture, allowing for a more concise and organized implementation. By sequentially adding layers using torch.nn.Sequential, developers can easily create complex MLP models while maintaining clarity and efficiency in their code structure.
Choose an appropriate activation function for each layer such as ReLU, Sigmoid, or Tanh.
When working with a multilayer perceptron in PyTorch, it is essential to select the right activation function for each layer to ensure optimal performance. Common choices include Rectified Linear Unit (ReLU) for hidden layers, Sigmoid for binary classification tasks, and Hyperbolic Tangent (Tanh) for capturing non-linear relationships. By carefully choosing the activation functions, you can enhance the network’s ability to learn complex patterns and improve its overall predictive power.
Initialize the weights of the model properly to prevent vanishing or exploding gradients.
Properly initializing the weights of a multilayer perceptron model in PyTorch is crucial to prevent issues such as vanishing or exploding gradients during training. By setting the initial weights intelligently, such as using techniques like Xavier initialization or He initialization, we can ensure that the gradients flow smoothly through the network layers, leading to more stable and efficient training. This simple yet essential tip can significantly impact the model’s performance and convergence speed, ultimately enhancing its overall effectiveness in learning complex patterns and making accurate predictions.
Split your dataset into training and validation sets to evaluate the performance of your MLP.
To enhance the evaluation of your Multilayer Perceptron model built with PyTorch, it is advisable to split your dataset into training and validation sets. By doing so, you can assess the performance of your MLP more effectively. The training set is used to train the model on the data, while the validation set helps in evaluating how well the model generalizes to unseen data. This approach enables you to fine-tune your MLP’s parameters and architecture based on its performance on the validation set, ultimately leading to a more robust and accurate neural network model.
Utilize techniques like dropout regularization to prevent overfitting in your MLP model.
To enhance the performance of your Multilayer Perceptron model built with PyTorch, it is advisable to incorporate techniques such as dropout regularization. By applying dropout to certain neurons during training, you can effectively prevent overfitting and improve the generalization ability of your MLP model. Dropout regularization helps in reducing the reliance on specific features or patterns in the data, leading to a more robust and reliable neural network that can better handle unseen data and produce more accurate predictions.
Experiment with different hyperparameters like learning rate, batch size, and number of epochs for better performance.
To optimize the performance of your Multilayer Perceptron model implemented in PyTorch, it is crucial to experiment with various hyperparameters such as learning rate, batch size, and number of epochs. Fine-tuning these hyperparameters can significantly impact the training process and ultimately enhance the model’s performance. By systematically adjusting these parameters and observing their effects on the model’s accuracy and convergence, you can identify the optimal configuration that maximizes efficiency and effectiveness in your neural network tasks.