The Power of Temporal Neural Networks in Machine Learning
Temporal neural networks have revolutionized the field of machine learning by enabling models to process and analyze sequential data with remarkable accuracy and efficiency. Unlike traditional feedforward neural networks, temporal neural networks are designed to capture and learn patterns from data that evolve over time.
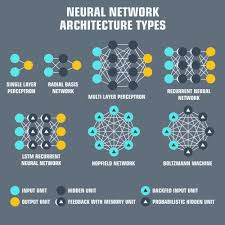
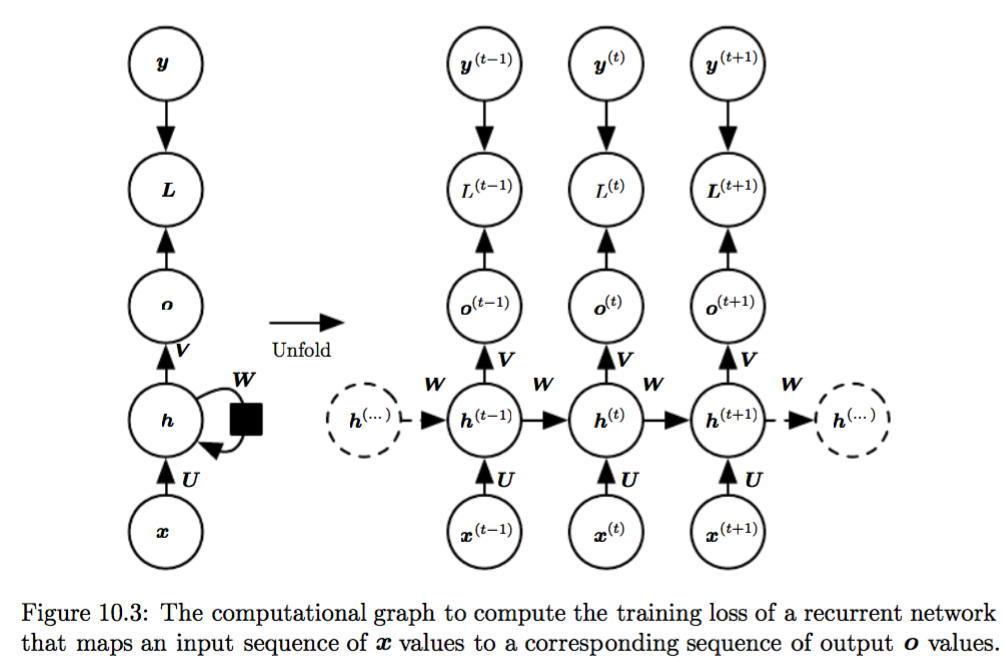
One of the key strengths of temporal neural networks is their ability to retain memory of past inputs, making them well-suited for tasks such as speech recognition, natural language processing, time series analysis, and more. By incorporating recurrent connections that allow information to persist through the network’s layers, temporal neural networks can effectively model complex temporal dependencies in data.
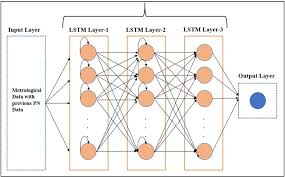
One popular type of temporal neural network is the Long Short-Term Memory (LSTM) network, which excels at capturing long-range dependencies in sequential data. LSTMs are equipped with specialized memory cells that can selectively store or discard information over time, enabling them to effectively handle sequences of varying lengths and complexities.
Another variant of temporal neural networks is the Gated Recurrent Unit (GRU), which offers a more streamlined architecture compared to LSTMs while still retaining powerful sequence modeling capabilities. GRUs use gating mechanisms to control the flow of information within the network, allowing them to learn from past inputs and make accurate predictions about future outcomes.
Overall, temporal neural networks have proven to be invaluable tools in a wide range of applications where understanding and processing sequential data is critical. Their ability to capture temporal dynamics and learn from historical context makes them indispensable for tasks that involve time-dependent patterns and relationships.
As researchers continue to explore new architectures and techniques for enhancing temporal neural networks, we can expect even greater advancements in machine learning capabilities that leverage the power of sequential data processing.
7 Essential Tips for Optimizing Temporal Neural Networks
- Use gated recurrent units (GRUs) or long short-term memory (LSTM) cells for capturing temporal dependencies.
- Consider using dilated convolutions to increase the receptive field of the network without increasing computational complexity.
- Regularize your model with techniques like dropout or weight decay to prevent overfitting on temporal data.
- Experiment with different activation functions such as ReLU, tanh, or sigmoid to find the most suitable one for your temporal neural network.
- Utilize batch normalization to stabilize and accelerate training by normalizing the activations in each layer.
- Adjust the learning rate dynamically using techniques like learning rate schedules or adaptive optimizers such as Adam or RMSprop.
- Visualize intermediate representations of your temporal neural network to gain insights into how information is processed at different layers.
Use gated recurrent units (GRUs) or long short-term memory (LSTM) cells for capturing temporal dependencies.
To effectively capture temporal dependencies in sequential data, it is recommended to utilize gated recurrent units (GRUs) or long short-term memory (LSTM) cells within your neural network architecture. These specialized units are designed to retain and process information over time, allowing the model to learn complex patterns and dependencies within the data sequence. By incorporating GRUs or LSTMs, you can enhance the network’s ability to understand and leverage temporal dynamics, making it well-equipped for tasks such as speech recognition, language modeling, and time series analysis.
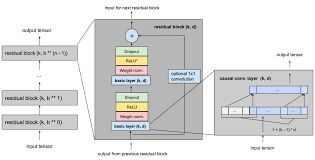
Consider using dilated convolutions to increase the receptive field of the network without increasing computational complexity.
By incorporating dilated convolutions in a temporal neural network, you can effectively increase the receptive field of the network without adding to the computational complexity. This innovative technique allows the network to capture larger contextual information from the input data, enabling it to better understand long-range dependencies and patterns in sequential data. By strategically applying dilations to convolutional layers, you can enhance the network’s ability to process temporal information efficiently and effectively, leading to improved performance in tasks such as speech recognition, video analysis, and time series forecasting.
Regularize your model with techniques like dropout or weight decay to prevent overfitting on temporal data.
Regularizing your temporal neural network model with techniques like dropout or weight decay is crucial to prevent overfitting on temporal data. Overfitting occurs when a model learns noise and irrelevant patterns from the training data, leading to poor generalization performance on unseen data. By incorporating regularization methods such as dropout, which randomly deactivates neurons during training, or weight decay, which penalizes large weights, you can help your model generalize better and improve its ability to capture meaningful temporal patterns without being overly sensitive to noise in the data.
Experiment with different activation functions such as ReLU, tanh, or sigmoid to find the most suitable one for your temporal neural network.
When working with temporal neural networks, it is essential to experiment with different activation functions like ReLU, tanh, or sigmoid to determine the most appropriate one for your specific model. Each activation function has unique characteristics that can impact the network’s performance in processing sequential data. By testing and comparing these functions, you can optimize the behavior of your temporal neural network and enhance its ability to capture and learn from temporal dependencies effectively.
Utilize batch normalization to stabilize and accelerate training by normalizing the activations in each layer.
To enhance the training process of temporal neural networks, it is recommended to incorporate batch normalization as a technique to stabilize and expedite the learning process. By normalizing the activations in each layer, batch normalization helps in mitigating issues such as vanishing or exploding gradients, thereby improving the overall stability and efficiency of the training process. This approach not only accelerates convergence during training but also enhances the network’s ability to learn meaningful representations from sequential data, ultimately leading to improved performance and generalization.
Adjust the learning rate dynamically using techniques like learning rate schedules or adaptive optimizers such as Adam or RMSprop.
To enhance the training efficiency and performance of temporal neural networks, it is recommended to adjust the learning rate dynamically throughout the optimization process. This can be achieved through techniques like learning rate schedules or by utilizing adaptive optimizers such as Adam or RMSprop. By dynamically modifying the learning rate based on the characteristics of the training data and the current state of the model, these methods help to prevent issues like slow convergence or overshooting during training. Adaptive optimizers, in particular, can automatically adjust the learning rate for each parameter in the network, leading to more stable and effective training of temporal neural networks.
Visualize intermediate representations of your temporal neural network to gain insights into how information is processed at different layers.
Visualizing intermediate representations of your temporal neural network can provide valuable insights into how information is processed at different layers. By examining the transformations that occur as data passes through the network’s hidden layers, you can gain a deeper understanding of how temporal dependencies are captured and encoded. This visualization technique allows you to identify patterns, anomalies, and relationships within the data, helping you optimize your model’s performance and interpret its decision-making process more effectively.