Speech Recognition Neural Network: Revolutionizing Communication
In today’s fast-paced world, technology continues to advance at an unprecedented rate, transforming the way we live, work, and communicate. One groundbreaking innovation that is revolutionizing communication is the Speech Recognition Neural Network.
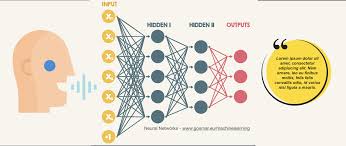
Speech recognition technology has come a long way since its inception, with neural networks playing a pivotal role in its evolution. A neural network is a type of artificial intelligence that mimics the human brain’s structure and functioning, enabling it to learn patterns and perform complex tasks.
When it comes to speech recognition, neural networks are trained on vast amounts of audio data to recognize and interpret spoken language accurately. By analyzing speech patterns and converting them into text or commands, these neural networks have enabled the development of voice-activated assistants, automated transcription services, and hands-free communication devices.
The applications of speech recognition neural networks are diverse and far-reaching. From improving accessibility for individuals with disabilities to enhancing customer service through interactive voice response systems, the impact of this technology is profound.
In addition to its practical applications, speech recognition neural networks are also driving innovation in fields such as healthcare, education, and entertainment. Voice-controlled medical devices can assist healthcare professionals in diagnosing patients more efficiently, while language learning apps can provide personalized feedback to students based on their pronunciation.
Looking ahead, the future of speech recognition neural networks holds even greater promise. As researchers continue to refine algorithms and improve model performance, we can expect even more accurate and seamless communication experiences across various platforms and devices.
In conclusion, speech recognition neural networks represent a significant milestone in the evolution of communication technology. By harnessing the power of artificial intelligence and machine learning, these innovative systems are shaping a world where spoken words are effortlessly understood and translated into meaningful actions.
8 Essential Tips for Optimizing Speech Recognition Neural Networks
- Ensure high-quality training data for better accuracy.
- Preprocess audio data to enhance model performance.
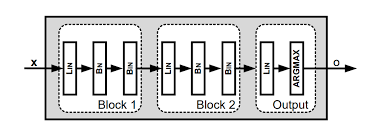
- Use deep learning architectures like CNNs or RNNs for speech recognition.
- Implement techniques like data augmentation to improve model generalization.
- Regularize the neural network to prevent overfitting.
- Experiment with different hyperparameters for optimal results.
- Consider using pre-trained models for faster development.
- Evaluate the model performance using metrics like WER and CER.
Ensure high-quality training data for better accuracy.
To maximize the accuracy of speech recognition neural networks, it is crucial to ensure high-quality training data. The quality of the data used to train the neural network directly impacts its ability to recognize and interpret spoken language effectively. By providing diverse, well-labeled, and error-free training data, developers can enhance the network’s performance and optimize its ability to accurately transcribe speech. Investing in high-quality training data is a key factor in improving the overall accuracy and reliability of speech recognition systems, ultimately leading to a more seamless and efficient communication experience for users.
Preprocess audio data to enhance model performance.
To optimize the performance of a speech recognition neural network, it is crucial to preprocess audio data effectively. By applying preprocessing techniques such as noise reduction, normalization, and feature extraction, the quality and clarity of the input data can be improved, leading to more accurate and reliable model predictions. Preprocessing audio data not only enhances the overall performance of the neural network but also helps in reducing errors and improving the efficiency of speech recognition systems.
Use deep learning architectures like CNNs or RNNs for speech recognition.
To enhance the accuracy and efficiency of speech recognition systems, it is recommended to leverage deep learning architectures such as Convolutional Neural Networks (CNNs) or Recurrent Neural Networks (RNNs). These sophisticated neural network models are well-suited for processing sequential data like speech signals, enabling them to capture intricate patterns and dependencies within spoken language. By utilizing CNNs or RNNs in speech recognition tasks, researchers and developers can achieve higher levels of accuracy and robustness, ultimately improving the overall performance and user experience of voice-controlled applications and services.
Implement techniques like data augmentation to improve model generalization.
To enhance the generalization of a speech recognition neural network model, implementing techniques such as data augmentation can be highly effective. By artificially expanding the training dataset through methods like adding noise, changing pitch, or altering speed, the model becomes more robust and better equipped to handle variations in speech patterns. This approach not only improves the model’s accuracy but also ensures that it can effectively recognize and transcribe speech in real-world scenarios with diverse acoustic conditions.
Regularize the neural network to prevent overfitting.
Regularizing the neural network is a crucial step in optimizing its performance and preventing overfitting. By incorporating regularization techniques, such as L1 or L2 regularization, dropout, or early stopping, the neural network can effectively generalize its learning from the training data to unseen data. This helps in improving the model’s accuracy and robustness, ensuring that it does not memorize noise or irrelevant patterns during training. Regularizing the neural network promotes better generalization capabilities, ultimately leading to more reliable and accurate speech recognition outcomes.
Experiment with different hyperparameters for optimal results.
To maximize the performance of your speech recognition neural network, it is essential to experiment with different hyperparameters to achieve optimal results. Hyperparameters such as learning rate, batch size, and network architecture play a crucial role in determining the accuracy and efficiency of the model. By systematically adjusting these parameters and observing their impact on the network’s performance, you can fine-tune your system to deliver the best possible results. Through careful experimentation and analysis, you can uncover the ideal combination of hyperparameters that will enhance the overall effectiveness of your speech recognition neural network.
Consider using pre-trained models for faster development.
When working with speech recognition neural networks, it is advisable to consider using pre-trained models to expedite the development process. Pre-trained models have already been trained on vast amounts of data and can provide a solid foundation for your project, saving time and resources. By leveraging these existing models, developers can focus on fine-tuning and customizing the network to suit their specific needs, leading to faster implementation and more efficient development of speech recognition applications.
Evaluate the model performance using metrics like WER and CER.
To assess the effectiveness of a speech recognition neural network model, it is crucial to evaluate its performance using metrics such as Word Error Rate (WER) and Character Error Rate (CER). WER measures the percentage of incorrectly recognized words in the transcribed text, providing insights into the overall accuracy of the model. On the other hand, CER calculates the proportion of incorrectly recognized characters, offering a more granular assessment of transcription errors. By analyzing these metrics, researchers and developers can fine-tune the neural network model to enhance its accuracy and efficiency in converting spoken language into text with greater precision.