Understanding Multilayer Neural Networks
In the field of artificial intelligence and machine learning, multilayer neural networks play a crucial role in solving complex problems that require high levels of abstraction and pattern recognition. These networks are designed to mimic the structure and function of the human brain, allowing them to learn from data and make intelligent decisions.
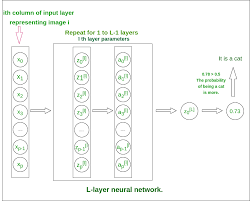
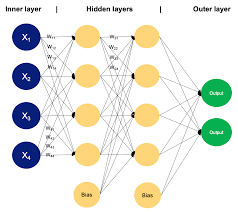
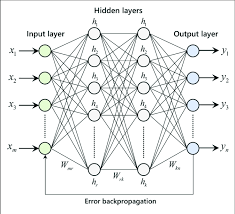
At its core, a multilayer neural network consists of multiple layers of interconnected nodes, or neurons. Each neuron receives input signals, processes them using weights and activation functions, and then passes the output to the next layer of neurons. By adjusting the weights during training, the network can learn to recognize patterns and make predictions based on the input data.
The key feature of multilayer neural networks is their ability to extract hierarchical representations of data. As information passes through each layer, the network can learn increasingly abstract features that capture the underlying structure of the data. This hierarchical approach allows neural networks to model complex relationships and make accurate predictions in a wide range of tasks.
One common type of multilayer neural network is the feedforward neural network, where information flows in one direction from input to output without any feedback loops. These networks are widely used in tasks such as image recognition, natural language processing, and speech recognition due to their ability to handle large amounts of data and extract meaningful features.
Another popular architecture is the convolutional neural network (CNN), which is specifically designed for processing grid-like data such as images. CNNs use specialized layers like convolutional layers and pooling layers to efficiently extract spatial hierarchies from images, making them highly effective for tasks like object detection and image classification.
In conclusion, multilayer neural networks are powerful tools that have revolutionized many areas of artificial intelligence. By leveraging their ability to learn complex patterns from data, these networks have enabled significant advancements in fields such as computer vision, natural language processing, and autonomous systems. As researchers continue to explore new architectures and techniques for training neural networks, we can expect even more exciting developments in the future.
7 Essential Tips for Optimizing Your Multilayer Neural Network
- Start with preprocessing your data to ensure it is in the right format for input to the neural network.
- Choose an appropriate activation function for each layer, such as ReLU for hidden layers and softmax for output layer.
- Experiment with different network architectures, including varying the number of layers and nodes, to find the optimal structure.
- Regularize your network using techniques like dropout or L2 regularization to prevent overfitting.
- Monitor training progress by tracking metrics like loss and accuracy to identify any issues or improvements needed.
- Use batch normalization to improve training speed and stability by normalizing inputs to each layer.
- Fine-tune hyperparameters such as learning rate, batch size, and optimizer choice through iterative experimentation.
Start with preprocessing your data to ensure it is in the right format for input to the neural network.
Before diving into training a multilayer neural network, it is essential to start with preprocessing your data to ensure that it is in the right format for input to the network. Data preprocessing involves tasks such as normalization, scaling, handling missing values, and encoding categorical variables. By preparing the data properly, you can improve the performance and efficiency of the neural network, as well as help prevent issues such as overfitting. This step sets a solid foundation for the training process and allows the network to learn effectively from the input data, leading to more accurate and reliable results in your machine learning tasks.
Choose an appropriate activation function for each layer, such as ReLU for hidden layers and softmax for output layer.
When working with a multilayer neural network, it is essential to carefully select the activation functions for each layer to ensure optimal performance. A common practice is to use the Rectified Linear Unit (ReLU) activation function for hidden layers, as it helps the network learn complex patterns efficiently by allowing for faster convergence during training. On the other hand, using the softmax activation function for the output layer is beneficial when dealing with classification tasks, as it produces a probability distribution over multiple classes, making it easier to interpret and make predictions based on the network’s output. By choosing appropriate activation functions for each layer, such as ReLU for hidden layers and softmax for the output layer, you can enhance the network’s learning capabilities and improve its overall accuracy in solving complex problems.
Experiment with different network architectures, including varying the number of layers and nodes, to find the optimal structure.
To optimize the performance of a multilayer neural network, it is essential to experiment with different network architectures. This involves varying the number of layers and nodes within the network to find the optimal structure that best suits the specific task at hand. By exploring different configurations, researchers and developers can fine-tune the network to achieve better accuracy, efficiency, and generalization capabilities. Through systematic experimentation and analysis of various architectures, one can uncover insights into how different design choices impact the network’s performance, leading to more effective neural network models for a wide range of applications.
Regularize your network using techniques like dropout or L2 regularization to prevent overfitting.
To enhance the performance and generalization of your multilayer neural network, it is essential to incorporate regularization techniques such as dropout or L2 regularization. These methods help prevent overfitting by imposing constraints on the network’s parameters during training. Dropout randomly deactivates a fraction of neurons in each training iteration, forcing the network to learn more robust and diverse features. On the other hand, L2 regularization adds a penalty term to the loss function based on the magnitude of weights, discouraging overly complex models. By regularizing your network effectively, you can improve its ability to generalize well to unseen data and achieve better overall performance in various machine learning tasks.
Monitor training progress by tracking metrics like loss and accuracy to identify any issues or improvements needed.
Monitoring the training progress of a multilayer neural network is essential for optimizing its performance and ensuring successful learning. By tracking key metrics such as loss and accuracy throughout the training process, developers can identify any issues or areas that require improvement. Loss metrics indicate how well the network is performing in terms of minimizing errors, while accuracy metrics measure the model’s ability to make correct predictions. By closely monitoring these metrics, developers can adjust parameters, fine-tune the network architecture, or modify the training data to enhance the network’s performance and achieve better results.
Use batch normalization to improve training speed and stability by normalizing inputs to each layer.
Batch normalization is a valuable technique in optimizing the training process of multilayer neural networks by normalizing inputs to each layer. By standardizing the input data within mini-batches during training, batch normalization helps improve the speed and stability of the learning process. This method reduces issues like vanishing or exploding gradients, which can hinder the convergence of the network during training. By ensuring that each layer receives inputs with consistent mean and variance, batch normalization promotes smoother and more efficient learning, ultimately enhancing the overall performance of the neural network.
Fine-tune hyperparameters such as learning rate, batch size, and optimizer choice through iterative experimentation.
To optimize the performance of a multilayer neural network, it is essential to fine-tune hyperparameters such as the learning rate, batch size, and choice of optimizer through iterative experimentation. These hyperparameters play a critical role in determining how quickly and effectively the network learns from data and adjusts its weights during training. By systematically varying these parameters and observing their impact on the network’s performance, researchers and practitioners can find the optimal configuration that maximizes accuracy and convergence speed. This iterative approach to hyperparameter tuning is key to unlocking the full potential of multilayer neural networks in solving complex real-world problems.