Exploring the Power of Computer Vision Neural Networks
In the realm of artificial intelligence, computer vision neural networks have emerged as a powerful tool for interpreting and understanding visual information. These sophisticated systems are designed to mimic the human visual system, enabling machines to analyze and make sense of images and videos with remarkable accuracy.
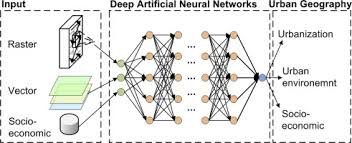
Computer vision neural networks are built on deep learning algorithms that are trained on vast amounts of labeled image data. By processing this data through multiple layers of interconnected nodes, these networks can extract features, recognize patterns, and classify objects within images.
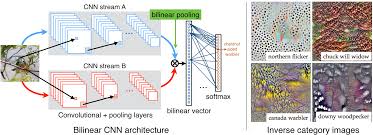
One key application of computer vision neural networks is in image recognition. These systems can identify objects, faces, text, and even emotions in images with incredible precision. This technology has revolutionized industries such as healthcare, security, automotive, and retail by enabling tasks like facial recognition, object detection, autonomous driving, and product recommendation systems.
Another important use case for computer vision neural networks is in image generation. Generative models like GANs (Generative Adversarial Networks) can create realistic images from scratch by learning the underlying patterns and structures present in a dataset. This capability has led to advancements in areas such as digital art, creative design, and content generation.
As computer vision neural networks continue to evolve and improve, their potential for impact across various domains is limitless. From enhancing medical diagnostics to improving surveillance systems to enabling immersive augmented reality experiences, these intelligent systems are reshaping the way we interact with visual information in the digital age.
Top 5 Tips for Enhancing Computer Vision Neural Network Performance
- Preprocess the input images to enhance features and improve model performance.
- Use data augmentation techniques to increase the diversity of your training dataset.
- Choose an appropriate neural network architecture based on the complexity of the computer vision task.
- Fine-tune pre-trained models to leverage transfer learning and improve training efficiency.
- Regularly evaluate and fine-tune hyperparameters to optimize model performance.
Preprocess the input images to enhance features and improve model performance.
When working with computer vision neural networks, a crucial tip is to preprocess the input images before feeding them into the model. By enhancing features through preprocessing techniques such as normalization, resizing, and augmentation, the model’s performance can be significantly improved. Preprocessing helps in standardizing the data, reducing noise, and highlighting important visual cues, ultimately leading to more accurate and reliable predictions from the neural network.
Use data augmentation techniques to increase the diversity of your training dataset.
To enhance the performance of your computer vision neural network, it is advisable to leverage data augmentation techniques to augment the diversity of your training dataset. By applying methods such as rotation, flipping, scaling, and adding noise to your existing images, you can generate new variations that help improve the network’s ability to generalize and recognize patterns effectively. This strategy not only boosts the robustness of the model but also ensures better accuracy and reliability in handling real-world visual data.
Choose an appropriate neural network architecture based on the complexity of the computer vision task.
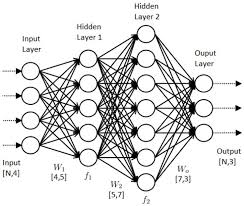
When working with computer vision tasks, it is crucial to select the right neural network architecture that aligns with the complexity of the task at hand. The choice of architecture plays a significant role in determining the performance and efficiency of the system. For simpler tasks like basic image classification, a less complex network structure may suffice to achieve accurate results without unnecessary computational overhead. On the other hand, for more intricate tasks such as object detection or image segmentation, a deeper and more sophisticated neural network architecture with advanced layers and features may be required to handle the complexity of the data and extract meaningful insights effectively. By carefully considering the complexity of the computer vision task, one can optimize the neural network architecture to ensure optimal performance and successful outcomes.
Fine-tune pre-trained models to leverage transfer learning and improve training efficiency.
Fine-tuning pre-trained models is a valuable tip in the realm of computer vision neural networks. By leveraging transfer learning, where a model trained on a large dataset is adapted to a new, smaller dataset, developers can significantly enhance training efficiency and performance. Fine-tuning allows the model to retain knowledge learned from the original dataset and adapt it to the specific characteristics of the new data, leading to faster convergence and improved accuracy. This approach not only saves time and computational resources but also enables developers to achieve impressive results with limited labeled data, making it a powerful strategy in optimizing the training process for computer vision tasks.
Regularly evaluate and fine-tune hyperparameters to optimize model performance.
Regularly evaluating and fine-tuning hyperparameters is a crucial tip in maximizing the performance of a computer vision neural network. Hyperparameters are parameters that control the learning process of the model, such as learning rate, batch size, and network architecture. By systematically adjusting these hyperparameters based on the model’s performance on validation data, researchers can optimize the neural network’s accuracy and efficiency. This iterative process of fine-tuning ensures that the model adapts to different datasets and tasks, leading to better generalization and overall performance in computer vision tasks.