Bayesian Learning for Neural Networks
Neural networks have revolutionized the field of artificial intelligence, enabling machines to perform complex tasks such as image recognition, natural language processing, and autonomous driving. However, one of the challenges associated with neural networks is their tendency to overfit data and their lack of uncertainty estimates in predictions. Bayesian learning offers a robust framework to address these issues by incorporating probabilistic reasoning into neural networks.
Understanding Bayesian Learning
Bayesian learning is a statistical approach that applies Bayes’ theorem to update the probability distribution of a model’s parameters based on observed data. In simple terms, it allows us to quantify our uncertainty about model parameters and make predictions that reflect this uncertainty.
Bayes’ Theorem:
P(θ|D) = (P(D|θ) * P(θ)) / P(D)
In this equation:
- P(θ|D) is the posterior distribution of the parameters θ given the data D.
- P(D|θ) is the likelihood of observing data D given parameters θ.
- P(θ) is the prior distribution of the parameters θ.
- P(D) is the marginal likelihood or evidence, which normalizes the posterior distribution.
Applying Bayesian Learning to Neural Networks
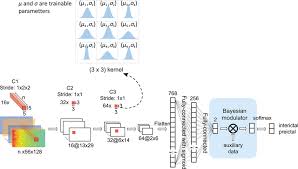
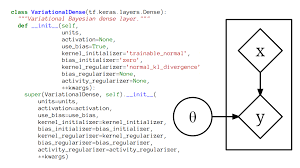
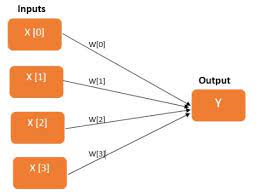
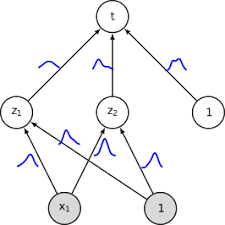
Traditional neural networks use point estimates for their weights and biases, which can lead to overconfidence in predictions. Bayesian neural networks (BNNs), on the other hand, treat these weights and biases as random variables with distributions that capture their uncertainty.
The process of training a BNN involves updating these distributions based on observed data using Bayes’ theorem. This allows BNNs to provide probabilistic predictions rather than deterministic ones. For example, instead of predicting a single class label for an image, a BNN can provide a probability distribution over all possible class labels.
Key Advantages of Bayesian Neural Networks
- Uncertainty Quantification: BNNs provide measures of uncertainty in their predictions, which are crucial for applications where decision-making under uncertainty is important.
- Avoiding Overfitting: By incorporating prior knowledge and regularizing through priors, BNNs are less prone to overfitting compared to traditional neural networks.
- Robustness: BNNs are more robust to noisy data and outliers due to their probabilistic nature.
Challenges and Future Directions
Despite their advantages, Bayesian neural networks come with some challenges:
- Computational Complexity: Training BNNs can be computationally intensive due to the need for sampling from complex distributions.
- Scalability: Scaling BNNs to very large datasets or deep architectures remains an active area of research.
The future of Bayesian learning for neural networks looks promising as researchers continue to develop more efficient algorithms and techniques. Advances such as variational inference and Monte Carlo methods are helping mitigate some computational challenges associated with BNNs.
Conclusion
Bayesian learning provides a powerful framework for enhancing neural networks by incorporating uncertainty into their predictions. While there are challenges related to computational complexity and scalability, ongoing research efforts are paving the way for more practical implementations. As these techniques mature, they hold great potential in making AI systems more reliable and trustworthy across various applications.
8 Essential Tips for Applying Bayesian Learning to Neural Networks
- Start with prior beliefs about the parameters of the neural network.
- Update your beliefs using new evidence (data) through Bayes’ theorem.
- Use Bayesian inference to estimate the posterior distribution of the parameters.
- Consider using Markov Chain Monte Carlo (MCMC) methods for sampling from complex posterior distributions.
- Regularize your neural network by incorporating prior knowledge into the model.
- Bayesian learning provides a principled way to deal with overfitting in neural networks.
- Explore variational inference as an alternative to MCMC for approximating posterior distributions.
- Understand the trade-offs between Bayesian learning and traditional optimization-based approaches.
Start with prior beliefs about the parameters of the neural network.
In Bayesian learning for neural networks, a key tip is to start with prior beliefs about the parameters of the network. By incorporating prior knowledge or assumptions about the distribution of the parameters before observing any data, we can guide the learning process and help prevent overfitting. These prior beliefs act as a regularization mechanism, influencing the posterior distribution of the parameters as data is observed and updating our understanding of the model’s uncertainty. This approach not only improves the robustness of neural networks but also enables us to make more informed decisions based on a combination of prior knowledge and observed evidence.
Update your beliefs using new evidence (data) through Bayes’ theorem.
To enhance the performance and reliability of neural networks using Bayesian learning, it is essential to update your beliefs based on new evidence or data using Bayes’ theorem. By incorporating the observed data into the model’s parameter distribution, you can refine your understanding and make more accurate predictions. This iterative process of updating beliefs allows neural networks to adapt to changing information and improve their overall performance by capturing uncertainties and adjusting their predictions accordingly.
Use Bayesian inference to estimate the posterior distribution of the parameters.
Bayesian inference is a powerful tool for estimating the posterior distribution of the parameters in neural networks, offering a way to incorporate prior knowledge and quantify uncertainty in model predictions. By applying Bayes’ theorem, one can update the probability distribution of the network’s weights and biases based on observed data. This process not only helps in avoiding overfitting by regularizing through priors but also provides a probabilistic framework that captures the inherent uncertainty of predictions. Consequently, using Bayesian inference allows for more robust and reliable AI models that can better handle noisy data and make well-informed decisions under uncertainty.
Consider using Markov Chain Monte Carlo (MCMC) methods for sampling from complex posterior distributions.
When delving into Bayesian learning for neural networks, it is advisable to explore the utilization of Markov Chain Monte Carlo (MCMC) methods for sampling from intricate posterior distributions. MCMC techniques offer a robust approach to capturing the uncertainty in model parameters by iteratively sampling from the posterior distribution. By employing MCMC methods, researchers can effectively navigate the complexities of Bayesian inference in neural networks, enabling more accurate and reliable probabilistic predictions.
Regularize your neural network by incorporating prior knowledge into the model.
To enhance the performance and reliability of your neural network, consider regularizing it by integrating prior knowledge into the model through Bayesian learning. By incorporating prior beliefs about the parameters of the neural network, you can effectively constrain the model’s complexity and prevent overfitting to the training data. This regularization technique not only improves the generalization ability of the network but also provides a more robust framework for making predictions by capturing uncertainties in the data. By blending domain expertise with Bayesian principles, you can create a more stable and trustworthy neural network that produces more accurate and meaningful results.
Bayesian learning provides a principled way to deal with overfitting in neural networks.
Bayesian learning offers a principled approach to address overfitting in neural networks. By treating the weights and biases as probabilistic variables with distributions that capture uncertainty, Bayesian learning helps prevent neural networks from memorizing noise in the training data and making overly confident predictions. This framework allows for more robust and generalizable models by incorporating prior knowledge and regularization techniques, ultimately improving the network’s performance on unseen data.
Explore variational inference as an alternative to MCMC for approximating posterior distributions.
When delving into Bayesian learning for neural networks, consider exploring variational inference as a compelling alternative to Markov Chain Monte Carlo (MCMC) methods for approximating posterior distributions. Variational inference offers a computationally efficient approach that aims to optimize a simpler distribution to approximate the complex posterior distribution. By leveraging variational inference techniques, researchers can streamline the process of training Bayesian neural networks and enhance their predictive capabilities with more scalable and practical implementations.
Understand the trade-offs between Bayesian learning and traditional optimization-based approaches.
It is essential to grasp the trade-offs between Bayesian learning and traditional optimization-based approaches when working with neural networks. While traditional optimization methods focus on finding a single set of parameters that minimize a specific loss function, Bayesian learning takes a probabilistic approach by considering parameter uncertainty. This difference leads to trade-offs in terms of computational complexity, interpretability, and generalization performance. Understanding these trade-offs is crucial for selecting the most suitable approach based on the specific requirements of the task at hand, balancing between deterministic optimization for efficiency and Bayesian learning for robustness and uncertainty quantification.