The Power of Convolutional Neural Networks: MNIST Example
Convolutional Neural Networks (CNNs) have revolutionized the field of image recognition and classification. One classic example that showcases the effectiveness of CNNs is the MNIST dataset, which consists of handwritten digits (0-9) and is widely used for training and testing machine learning models.
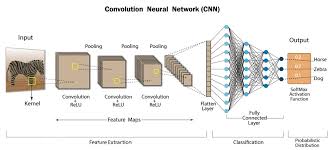
When working with the MNIST dataset, a CNN can efficiently learn to recognize and classify handwritten digits with high accuracy. The key components of a CNN include convolutional layers, pooling layers, and fully connected layers.
In a CNN designed for the MNIST dataset, the convolutional layers extract features from the input images by applying filters that detect patterns such as edges, corners, and textures. The pooling layers then downsample the extracted features to reduce computational complexity while preserving important information.
After multiple convolutional and pooling layers, the final output is fed into fully connected layers that perform classification based on the learned features. Through backpropagation and optimization algorithms like gradient descent, the CNN learns to minimize prediction errors and improve accuracy over time.
The performance of a CNN on the MNIST dataset can be evaluated using metrics such as accuracy, precision, recall, and F1 score. By fine-tuning hyperparameters, adjusting network architecture, and optimizing training procedures, researchers and developers can achieve impressive results in digit recognition tasks.
In conclusion, convolutional neural networks have proven to be highly effective in handling image data like the MNIST dataset. Their ability to automatically learn hierarchical features from raw pixel values makes them invaluable tools for image classification tasks across various domains.
Unlocking the Secrets of MNIST: A Guide to Convolutional Neural Networks for Digit Recognition
- What is the MNIST dataset?
- Why is the MNIST dataset commonly used for training convolutional neural networks?
- How do convolutional neural networks (CNNs) work with the MNIST dataset?
- What are the key components of a CNN when working with the MNIST dataset?
- How can one evaluate the performance of a CNN on the MNIST dataset?
- What strategies can be used to improve the accuracy of a CNN on digit recognition tasks using the MNIST dataset?
What is the MNIST dataset?
The MNIST dataset is a widely recognized and frequently discussed collection of handwritten digit images used for training and testing machine learning models, particularly in the context of convolutional neural networks (CNNs). Comprising grayscale images of digits ranging from 0 to 9, the MNIST dataset serves as a benchmark for evaluating the performance of image recognition algorithms. Researchers and developers often turn to the MNIST dataset to showcase the capabilities of CNNs in accurately classifying handwritten digits through pattern recognition and feature extraction. Its simplicity, accessibility, and standardized format make the MNIST dataset a popular choice for beginners and experts alike in the field of deep learning.
Why is the MNIST dataset commonly used for training convolutional neural networks?
The MNIST dataset is commonly used for training convolutional neural networks due to several key reasons. Firstly, the dataset is well-established and widely recognized in the machine learning community, making it a standard benchmark for evaluating the performance of new models and algorithms. Secondly, the simplicity and uniformity of the dataset, consisting of grayscale images of handwritten digits (0-9), make it ideal for testing the effectiveness of CNNs in image recognition tasks. Additionally, the relatively small size of the MNIST dataset allows for quick experimentation and iteration during model development, enabling researchers and developers to efficiently explore different network architectures and hyperparameters. Overall, the MNIST dataset serves as a foundational resource for understanding and improving the capabilities of convolutional neural networks in image classification applications.
How do convolutional neural networks (CNNs) work with the MNIST dataset?
Convolutional Neural Networks (CNNs) excel at processing image data like the MNIST dataset by leveraging their unique architecture. When working with the MNIST dataset, CNNs employ convolutional layers to extract features from handwritten digit images, such as edges and patterns. These features are then passed through pooling layers to downsample and retain essential information. By iteratively applying convolutional and pooling layers, CNNs learn hierarchical representations of the input data, enabling them to recognize and classify digits with high accuracy. Through training on labeled examples and adjusting parameters, CNNs fine-tune their internal weights to optimize performance on the MNIST dataset, showcasing their capability to effectively handle image classification tasks.
What are the key components of a CNN when working with the MNIST dataset?
When working with the MNIST dataset, the key components of a Convolutional Neural Network (CNN) play a crucial role in extracting and processing information from handwritten digit images. These components include convolutional layers, which apply filters to detect patterns like edges and textures; pooling layers, which downsample feature maps to reduce complexity while retaining important details; and fully connected layers, which perform classification based on the learned features. By leveraging these components effectively, a CNN can learn to recognize and classify handwritten digits with high accuracy, showcasing the power of this architecture in image recognition tasks.
How can one evaluate the performance of a CNN on the MNIST dataset?
Evaluating the performance of a Convolutional Neural Network (CNN) on the MNIST dataset involves assessing its ability to accurately classify handwritten digits. Common metrics used for evaluation include accuracy, precision, recall, and F1 score. Accuracy measures the overall correctness of the model’s predictions, while precision quantifies the proportion of correctly predicted positive instances out of all instances predicted as positive. Recall calculates the percentage of actual positive instances that were correctly identified by the model. The F1 score combines precision and recall into a single metric, providing a balanced assessment of the model’s performance. By analyzing these metrics and adjusting parameters such as network architecture and training procedures, researchers can gain valuable insights into the CNN’s effectiveness in digit recognition tasks on the MNIST dataset.
What strategies can be used to improve the accuracy of a CNN on digit recognition tasks using the MNIST dataset?
To enhance the accuracy of a Convolutional Neural Network (CNN) on digit recognition tasks using the MNIST dataset, several strategies can be implemented. Firstly, adjusting the network architecture by adding more convolutional layers or increasing the depth of existing layers can help capture intricate features in the input images. Secondly, incorporating regularization techniques such as dropout or L2 regularization can prevent overfitting and improve generalization performance. Additionally, data augmentation methods like rotation, scaling, and flipping can increase the diversity of training samples and enhance the model’s robustness. Fine-tuning hyperparameters such as learning rate, batch size, and optimizer choice through systematic experimentation can also lead to improved accuracy. Lastly, leveraging pre-trained models or ensembling multiple CNNs with different architectures can further boost performance on digit recognition tasks with the MNIST dataset.