The Power of Sparse Neural Networks in Machine Learning
Neural networks have revolutionized the field of machine learning, enabling computers to perform complex tasks with remarkable accuracy. One innovative approach that has gained traction in recent years is sparse neural networks.
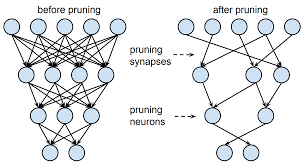
So, what exactly are sparse neural networks? Unlike traditional dense neural networks where every neuron is connected to every other neuron in the adjacent layers, sparse neural networks contain only a subset of connections. This sparsity leads to more efficient computation and reduced memory requirements, making them ideal for large-scale applications.
One key advantage of sparse neural networks is their ability to enhance model interpretability. By focusing on a smaller subset of connections, these networks can highlight the most important features and relationships within the data, leading to more transparent and understandable models.
Moreover, sparse neural networks offer improved computational efficiency. With fewer connections to compute during training and inference, these networks can achieve comparable performance to dense networks while requiring less computational resources. This efficiency is particularly beneficial for real-time applications and resource-constrained environments.
Another benefit of sparse neural networks is their enhanced generalization capability. By encouraging sparsity during training, these networks are less prone to overfitting and can better generalize to unseen data. This results in more robust models that perform well across a variety of scenarios.
As researchers continue to explore the potential of sparse neural networks, we can expect further advancements in model optimization, training algorithms, and deployment strategies. With their unique advantages in interpretability, efficiency, and generalization, sparse neural networks are poised to play a significant role in the future of machine learning and artificial intelligence.
8 Effective Strategies to Achieve Sparsity in Neural Networks
- Use regularization techniques like L1 or L2 regularization to encourage sparsity in the network.
- Utilize dropout during training to prevent overfitting and promote sparsity.
- Consider using pruning techniques to remove connections with low importance, reducing the network’s size and encouraging sparsity.
- Experiment with different activation functions that promote sparsity, such as ReLU or Leaky ReLU.
- Implement batch normalization to stabilize training and improve the efficiency of sparse neural networks.
- Explore group lasso regularization to enforce group-wise sparsity in certain layers of the network.
- Try using a combination of weight sharing and sparse connectivity patterns to reduce redundancy in the network.
- Opt for architectures like autoencoders or variational autoencoders that naturally learn sparse representations.
Use regularization techniques like L1 or L2 regularization to encourage sparsity in the network.
To promote sparsity in a neural network, employing regularization techniques such as L1 or L2 regularization can be highly effective. By adding a penalty term to the loss function based on the weights of the network, these techniques encourage the model to prioritize important features while pushing less relevant ones towards zero. This regularization helps prevent overfitting and enhances the interpretability of the network by promoting a sparse structure that focuses on key connections, ultimately leading to more efficient and effective neural network models.
Utilize dropout during training to prevent overfitting and promote sparsity.
To enhance the performance and efficiency of sparse neural networks, it is recommended to incorporate dropout during the training process. Dropout is a regularization technique that randomly deactivates a portion of neurons during each training iteration, preventing overfitting by promoting sparsity and reducing reliance on individual neurons. By introducing dropout, the network learns to be more robust and generalizes better to unseen data, ultimately improving its overall performance and adaptability.
Consider using pruning techniques to remove connections with low importance, reducing the network’s size and encouraging sparsity.
When working with sparse neural networks, it is beneficial to consider implementing pruning techniques to eliminate connections with low importance. By selectively removing these less critical connections, the network’s overall size is reduced, promoting sparsity and enhancing efficiency. This approach not only helps streamline the model but also encourages better interpretability and generalization by focusing on the most relevant features and relationships within the data.
Experiment with different activation functions that promote sparsity, such as ReLU or Leaky ReLU.
To enhance the sparsity of a neural network, it is beneficial to experiment with different activation functions that encourage sparsity, such as Rectified Linear Unit (ReLU) or Leaky ReLU. These activation functions introduce non-linearity into the network while allowing certain neurons to remain inactive, thus promoting sparsity in the network’s connections. By exploring the effects of different activation functions, researchers and practitioners can optimize the sparsity of neural networks and improve their interpretability, efficiency, and generalization capabilities.
Implement batch normalization to stabilize training and improve the efficiency of sparse neural networks.
To enhance the training stability and efficiency of sparse neural networks, implementing batch normalization is a valuable tip. Batch normalization helps in normalizing the input to each layer during training, which stabilizes the learning process and accelerates convergence. By incorporating batch normalization into sparse neural networks, it becomes easier to train deeper models effectively while mitigating issues like vanishing or exploding gradients. This technique not only enhances the overall performance of sparse neural networks but also contributes to faster training times and improved model generalization.
Explore group lasso regularization to enforce group-wise sparsity in certain layers of the network.
To enhance the sparsity of specific layers in a neural network, consider exploring group lasso regularization. This technique enforces group-wise sparsity by encouraging entire groups of parameters to be either active or inactive together, leading to a more structured and interpretable model. By applying group lasso regularization selectively to certain layers, you can effectively control the level of sparsity in those layers and improve the overall efficiency and performance of the network.
Try using a combination of weight sharing and sparse connectivity patterns to reduce redundancy in the network.
To enhance the efficiency and performance of sparse neural networks, consider implementing a combination of weight sharing and sparse connectivity patterns. By sharing weights among neurons and incorporating sparse connections, you can effectively reduce redundancy in the network structure. This approach not only optimizes computational resources but also promotes better model interpretability and generalization, leading to more streamlined and effective neural network architectures.
Opt for architectures like autoencoders or variational autoencoders that naturally learn sparse representations.
When working with sparse neural networks, it is beneficial to consider architectures such as autoencoders or variational autoencoders. These models are designed to naturally learn sparse representations of data, making them well-suited for tasks where interpretability and efficiency are key priorities. By leveraging the inherent sparsity capabilities of autoencoders and variational autoencoders, developers can create more streamlined and effective neural network architectures that excel in capturing essential features while minimizing computational overhead.