Understanding the Two-Layer Neural Network
In the realm of artificial intelligence (AI) and machine learning, neural networks are among the most prominent tools used for pattern recognition and predictive modeling. At their core, neural networks are inspired by the biological neural networks that constitute animal brains. A two-layer neural network, often referred to as a single hidden layer network, is a fundamental architecture that plays a crucial role in understanding more complex models.
What is a Two-Layer Neural Network?
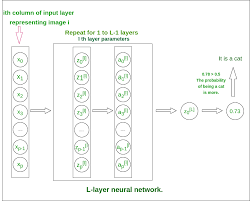
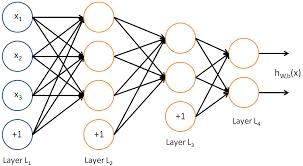
A two-layer neural network consists of an input layer, one hidden layer, and an output layer. Although it’s called a “two-layer” network, this nomenclature typically doesn’t count the input layer—thus focusing on the layers that have weights and can learn from data.
- Input Layer: The first layer receives the input features. It’s responsible for passing the information to the hidden layer without applying any transformations or learning.
- Hidden Layer: This is where intermediate processing or computation occurs. Each neuron in this layer applies a set of weights to its inputs and passes them through an activation function which introduces non-linearity into the model.
- Output Layer: The final layer produces the output of the network. For classification tasks, this could be probabilities of belonging to certain classes; for regression tasks, it might be continuous values.
The Role of Activation Functions
The activation function in a neural network is crucial as it introduces non-linear properties to the system. Without non-linearity, no matter how many layers are added to the network, it would still behave like a single-layer perceptron with limited capabilities. Common activation functions include sigmoid, tanh, ReLU (Rectified Linear Unit), and softmax for multi-class classification tasks.
Training Two-Layer Neural Networks
To train these networks effectively, backpropagation algorithms are used alongside optimization techniques like gradient descent. During training:
- Data is fed forward through the network to produce an output.
- The output is compared against true values using a loss function to calculate error.
- The error is then propagated back through the network (backpropagation), allowing weights to be updated accordingly.
This process iterates many times over training datasets allowing weights and biases in both layers to adjust their values in order to minimize loss and improve prediction accuracy.
Applications of Two-Layer Neural Networks
Despite their simplicity relative to deeper networks with multiple hidden layers (deep learning), two-layer neural networks have been successfully applied in various domains such as:
- Digital character recognition
- Basic image classification tasks
- Preliminary financial forecasting models
- Sentiment analysis on textual data
Limits and Beyond Two Layers
A two-layer neural network can represent complex decision boundaries but may struggle with highly intricate data structures that deeper networks can capture. As problems become more complex requiring nuanced feature extraction—such as in speech recognition or high-resolution image processing—networks with additional hidden layers (deep learning) become necessary for capturing higher levels of abstraction within data.
Conclusion
A two-layer neural network serves as both a practical tool for certain applications and an educational stepping-stone towards understanding more complex deep learning architectures. Its simplicity allows researchers and practitioners alike to grasp fundamental concepts such as forward propagation, backpropagation, activation functions, loss calculations, and weight updates—all essential components of modern AI systems.
Six Essential Tips for Optimizing Two-Layer Neural Networks: From Data Preparation to Performance Monitoring
- Ensure proper data preprocessing and normalization before training the neural network.
- Experiment with different activation functions such as ReLU, sigmoid, or tanh to find the most suitable one for your model.
- Choose an appropriate loss function based on the nature of your problem (e.g., cross-entropy for classification tasks).
- Regularize the model using techniques like L1 or L2 regularization to prevent overfitting.
- Optimize hyperparameters such as learning rate, batch size, and number of neurons in each layer through experimentation and tuning.
- Monitor the training process by visualizing metrics like loss and accuracy to assess the model’s performance.
Ensure proper data preprocessing and normalization before training the neural network.
To maximize the effectiveness of a two-layer neural network, it is crucial to prioritize proper data preprocessing and normalization before initiating the training process. By preprocessing the data, such as handling missing values, removing outliers, and encoding categorical variables, we can ensure that the neural network receives clean and structured input. Additionally, normalization techniques like scaling features to a similar range or standardizing them can help prevent certain inputs from dominating others during training, leading to more stable and efficient learning outcomes. Overall, investing time in preparing and normalizing the data sets a strong foundation for the neural network to learn effectively and make accurate predictions.
Experiment with different activation functions such as ReLU, sigmoid, or tanh to find the most suitable one for your model.
To enhance the performance of your two-layer neural network, it is recommended to experiment with various activation functions like ReLU, sigmoid, or tanh. Each activation function introduces different non-linear properties to the network, impacting its learning capabilities and overall accuracy. By testing different activation functions and observing their effects on training and validation results, you can determine the most suitable one that improves the efficiency and effectiveness of your model for specific tasks or datasets.
Choose an appropriate loss function based on the nature of your problem (e.g., cross-entropy for classification tasks).
When working with a two-layer neural network, it is crucial to select the right loss function that aligns with the specific nature of your problem. For classification tasks, where the goal is to assign inputs to distinct categories, using a loss function like cross-entropy can be highly effective. Cross-entropy loss is particularly well-suited for classification problems as it measures the difference between predicted class probabilities and actual class labels, providing a clear indication of how well the model is performing in terms of classification accuracy. By choosing an appropriate loss function tailored to your problem domain, you can enhance the overall performance and reliability of your neural network.
Regularize the model using techniques like L1 or L2 regularization to prevent overfitting.
Regularizing a two-layer neural network using techniques like L1 or L2 regularization is essential to prevent overfitting. Overfitting occurs when a model learns the noise and details in the training data to the extent that it negatively impacts its ability to generalize well on unseen data. By incorporating regularization methods, such as adding penalty terms to the loss function based on the magnitudes of weights (L1 regularization) or their squared values (L2 regularization), the model is encouraged to focus on important features and avoid overly complex representations. This helps improve the model’s generalization performance and ensures that it can make accurate predictions on new data beyond the training set.
Optimize hyperparameters such as learning rate, batch size, and number of neurons in each layer through experimentation and tuning.
To enhance the performance and efficiency of a two-layer neural network, it is crucial to optimize hyperparameters such as the learning rate, batch size, and the number of neurons in each layer through systematic experimentation and tuning. The learning rate determines how quickly the model adapts to the data, while the batch size affects the stability and speed of training. Additionally, adjusting the number of neurons in each layer can significantly impact the network’s capacity to learn complex patterns. By iteratively testing different configurations and fine-tuning these hyperparameters, researchers and practitioners can maximize the network’s predictive power and optimize its overall performance for specific tasks.
Monitor the training process by visualizing metrics like loss and accuracy to assess the model’s performance.
It is essential to monitor the training process of a two-layer neural network by visualizing metrics such as loss and accuracy. By keeping a close eye on these indicators, you can assess the model’s performance and make informed decisions about adjustments or optimizations that may be necessary. Tracking loss helps in understanding how well the model is learning from the data, while monitoring accuracy provides insights into the model’s predictive capabilities. Visualizing these metrics allows for real-time feedback on the network’s progress, enabling you to fine-tune parameters and improve overall performance effectively.